This post describes my fun project to solve the Queen problem in multiple languages and compare their execution runtimes.
Let me first show you the results plot …

… and then take you through the journey.
Content Waypoints
- Motivation and Flashback
- Solution Explanation
- Project Plan
- Solution Structure
- Live Results
- What’s coming up next?
Motivation and Flashback
I have not (yet?) formally studied Computer Science. Rather, I gained my knowledge, skills, and experience through self-learning during my professional career. I discovered the Queen problem about 15 years ago. For several years, I struggled to grasp the backtracking that the solutions mentioned, and particularly, how it was different from brute force.
Then one fateful day in 2018, I found Abdul Bari’s YouTube video. His clear explanation helped me easily understand the backtracking. [I binge-watched his other videos later and realized—like many others before and after me—that he is an amazing teacher!]
To verify my understanding, I quickly prototyped a solution in C++ on ideone. [Interestingly, when I accidentally resubmitted the solution recently, it failed to compile due to the constexpr in the template parameter.]
I did nothing more on it until mid-2024. During this time, I gained more experience with Python. I self-learned CI/CD pipelines, both Github Actions and Gitlab CI. A few weeks ago, I started learning Rust. Putting together all these skills seemed like a fun project. Thus, I revisited the Queen problem.
Solution Explanation
I decided to continue with my prototype solution and deal with improving it later.
My prototype solution is based on the following main ideas: [Of course, nothing groundbreaking—thousands of others have solved it before me.]
- Pigeonhole Principle: Since each Queen occupies an entire row and column, we cannot place more than one Queen on a row or a column. Conversely, a solution to the N-Queen problem (placing N Queens on an NxN chessboard) cannot have any empty row or column. [As embarassing at it sounds in hindsight, this was a key factor I had failed to realize before, due to which I couldn’t differentiate backtracking from brute force.]
-
Calculating the Queen’s attack along the diagonals: Similarly, we cannot place more than one Queen on any diagonal. Calculating the Queen’s attack along diagonals is a little more complicated, though. I’ll explain my approach to this later, but first, it is time for some chess ज्ञान (gyan).

Chess Gyan
- The horizontal rows on a chessboard are called ranks (labelled
1through8, bottom to top), while the vertical columns are called files (labelledathroughh, left to right). Nonetheless, in this blog post, I’ll call them rows and columns, numbered0through7top to bottom and left to right respectively. - The Queen is the most powerful piece in chess, which controls between 22 and 28 squares on an 8x8 chessboard. That’s a control of 34.38% to 43.75% squares. This makes the Queen problem all the more fascinating. Not only can we place 8 Queens on an 8x8 chessboard without an overlap of their controlled squares, but we can do so in 92 different positions!


Calculation of the diagonal attacks
When making my prototype, I referred some previous solutions. Many of them used the Queen’s row and column position to check if it would occupy the same diagonal as any of the previously placed Queens. I took a different approach, which is equivalent but felt easier to understand and implement.
I numbered each diagonal, in both directions, so I could maintain an array of flags to represent if a diagonal was already occupied. This is possible because the combination of row and column number satisfy an invariant along each diagonal:
- Right diagonals: The sum of the row and column numbers is the same for all squares on a diagonal going up towards the right. This sum can be used to number the diagonals.
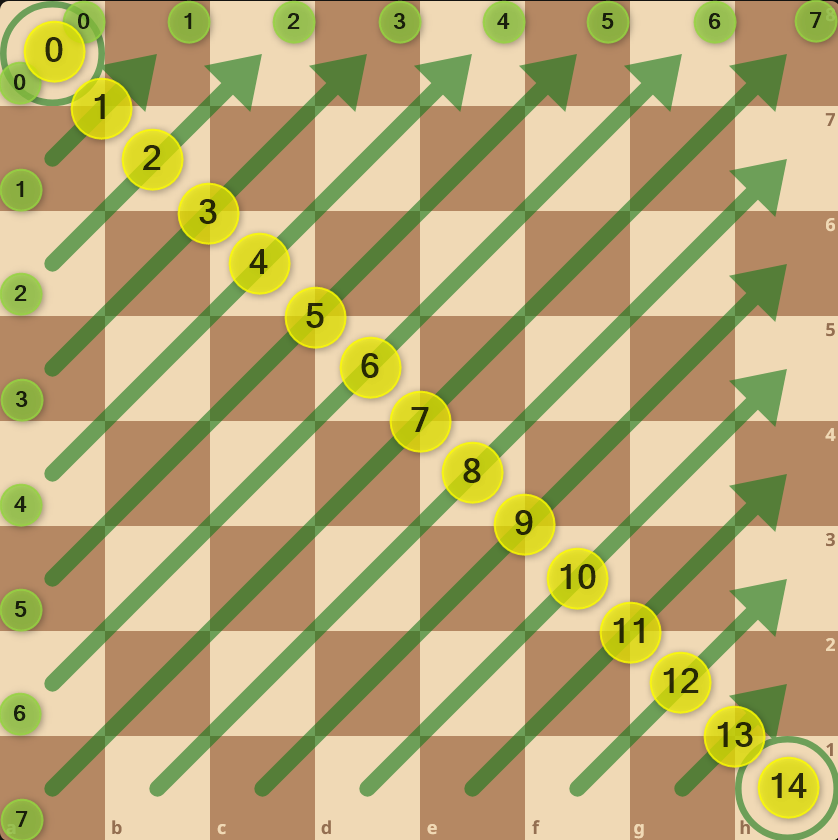
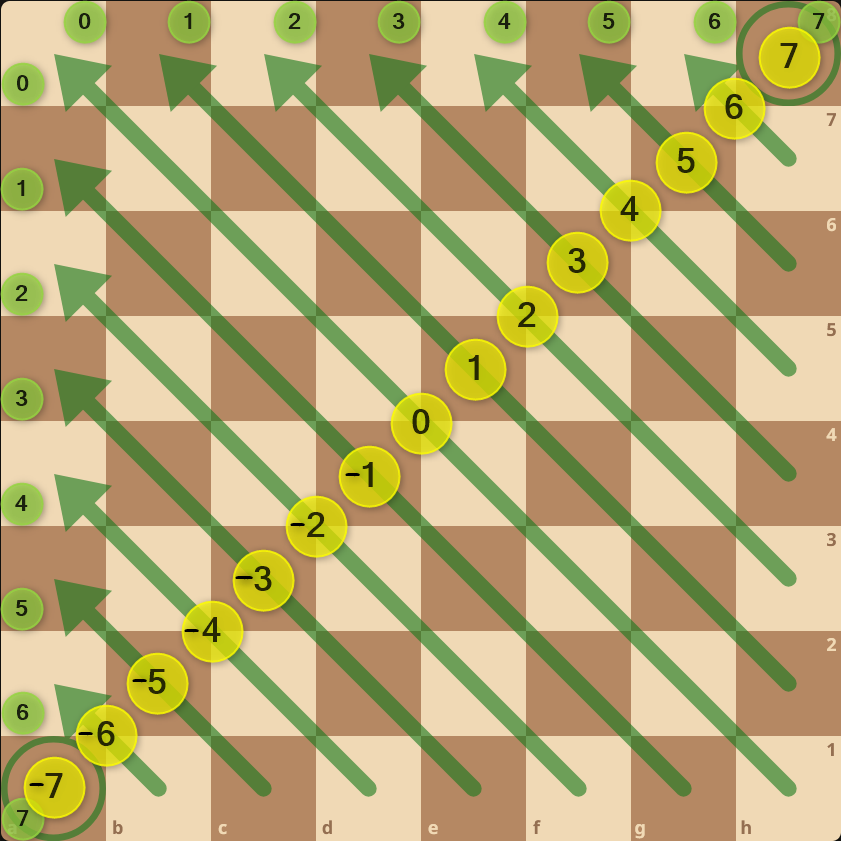
- Left diagonals: The difference between the row and column numbers is the same for all squares on a diagonal going up towards the left. This difference can be used to number the diagonals.
Prototype Algorithm
-
Let each Queen move only along one column. The column number also serves as the Queen’s identity. Due to the Pigeonhole Principle mentioned earlier, there is a 1:1 mapping between a Queen and a column. [Equivalently, a Queen could move only along a row, but personally, I found the column mapping more intuitive.]

Let each Queen can move only along one column. -
Pseudo-code of the prototype algorithm:
let ROW = 0 for COLUMN from 0 to N - 1 (both inclusive): { if ROW, COLUMN, and both diagonals are not occupied: { (1) place Queen in column number 'COLUMN' [For the row number 'ROW', note occupied column number as 'COLUMN'] (2) mark ROW, COLUMN, and both diagonals as occupied if ROW < N: // there are still unoccupied rows { let ROW = ROW + 1 attempt to place a Queen in (ROW + 1) using the approach in (1) and (2) } else: { // We checked the occupancy status along rows, columns and diagonals // before placing a Queen. If we have reached here, we must have placed // N queens successfully without conflict. We found a solution! print solution // occupied column number in each row denotes the solution } // When we reach here, we have either found a solution or failed to place a // Queen in one of the rows without conflict. In either case, we move on to // search for the next solution with a clean slate. mark ROW, COLUMN, and both diagonals as unoccupied } } -
Implementation Details
- This algorithm naturally leans towards a recursion-based implementation.
- As only one column can be occupied in any row, a one-dimensional array is adequate to note the positions of the Queens. This array also tracks the row occupancy status.
- One-dimensional arrays can denote occupancy of columns and diagonals.
- The left diagonals are numbered from
-(N-1)to+(N+1), but arrays in most programming languages support only non-negative indexes. Hence, an offset should be added to bring the left diagonal numbers within the non-negative range. - The prototype does not store the solutions. Instead, it immediately prints solutions as they are found.
Project Plan
To expand my prototype into a project, I structured the following project plan:
-
Step 1: Move my 2018 prototype to my Github repository as-is. Rework the solution to accept
Nas a command-line input instead of the template parameter. Fix some bugs and write better code documentation. - Step 2: Translate the solution into Python and Rust. To level the playing field, if you will, use the same algorithm in both of those languages.
- Step 3: Develop scripts to run the solutions and plot the execution times, for both pipeline build and local developer builds.
-
Step 4: Share the first version of the solutions and performance results publicly, for example, in this blog post!
- Step 5: To be revealed in Part 2!
Storing the result artifacts
To have even more fun, I initially considered connecting an external artifact repository to store the result artifacts. Unfortunately, the service I had in mind (the one with the small jumping animal) was too pricey for a hobby project. Hence, I opted to use Github itself as the artifact repository for now, and explore alternatives later.
Execution times would be stored in CSV format, and used to plot graphs in SVG format. By sticking to these text-based formats, I avoid the shenanigans of LFS (Large File Storage)—though BFS (Binary File Storage) would be a more accurate name!
Solution Structure
You can find the project on my Github repository: dragondive/queen [Code reviews and other contributions are welcome!]
- Solutions are developed on the
develop/queenbranch, with a separate directory for each language.- My unoptimized prototype in C++, the project’s lead language, is here.
- Github Actions workflows are currently developed directly on the main branch.
- The workflow that measures solution execution times and updates the plots is here.
- Solution artifacts are stored on the
artifactsbranch in theartifactsdirectory. -
Conventional commits, squashed commits and controlled force pushing maintain a clean commit history [With controlled force pushing and interactive rebase, I changed the
README.mdin the initial commit toREADME.rstand performed several other commit history cleanups retroactively.] - Tagging the solution versions and running the pipeline jobs is done manually for now.
Live Results
Execution times for each solution language and version are plotted against N, considering average values. Each successful pipeline build updates the plot, making them live plots.
The log scale plot provides a more insightful visualization than the linear scale plot. Nonetheless, the pipeline build updates both the plots:


Results interpretation
The most obvious observation is that the C++ solution is the fastest, with Rust close behind, and Python being significantly slower. However, execution time alone should not dictate the choice of language for a particular problem. In my opinion, rules like “never do this” and “always do that” are never helpful and always ignorable.
This topic has sparked much discussion, controversy and misinformation in both developer and sustainability communities. The debate intensified around 2021 when the 2017 research paper Energy Efficiency across Programming Languages reentered prominence. That debate was also a motivator for me to revive this fun project, as both software development and sustainability are of great interest to me. [It took me a few years though to get around to it.] See also Yelle Lieder’s blog post on the topic: Sustainability of programming languages: Java rather than TypeScript?
Personally, I enjoy using both C++ and Python, among other languages. My choice of language for a particular problem is made on a case-by-case basis, and depends on several factors:
- Learning time: How long it takes me (and my team) to learn the language, or in some cases, its specific “advanced” features.
- Development time: The time required to write the code. In some cases, it’s no good if your program runs 100 ms faster but takes three more months to develop.
- Build time: The time it takes to build and deploy the application.
- Debug time: As with everything else in the world, software goes wrong, sooner or later. The amount of time (and occasionally, frustration) it takes to fix problems also matters.
- Documentation, testability and team composition: Most non-trivial software is developed by a team of developers. The ease of understanding and reliably modifying others’ codes, especially in teams distributed across distant timezones, impacts code quality and value of the application.
- Availability of useful libraries and active community: These reduce development and maintenance efforts.
- Availability of enthusiastic developers: Ease of finding developers, especially at work, interested in using the language significantly impacts planning. I have encountered scenarios where developers refused job offers or even interview invitations because they didn’t want to work with a specific framework being used [which was understandable as the framework was company-proprietary and completely different from the industry standards].
- The frequency of use of the application: An application used several times per day benefits from high efficiency. One that is used only a few times per year, perhaps not so much.
Comparing languages solely by execution time without considering the full context is too simplistic. In particular, a “faster” language is not necessarily “greener”. As developers, we should make data-driven decisions objectively, based on many diverse but relevant factors, without being biased towards our favourite language or the “flavour of the month” language.
What’s coming up next?
I will optimize and partially rework my prototype. Specifically, I’ll replace the recursion with iteration and use a more efficient approach for reporting results instead of the repeated I/O access. I will share my findings in the Part 3 of this blog post.
Hang on! What about Part 2? I’ll be solving the Queen problem using a fourth language—one that is different, more interesting and more fun than these three. Can you guess which language that will be? Let me know in the comments!
[Update: The fourth language is PlantUML! Read more in Part 2: PlantUML to compute diagrams!]
Tools Used
- Lichess board editor for the chessboard annotations.
- Screenpresso image editor for the numbered circles. The tool doesn’t support negative numbers, so I manually edited in the minus sign. [Disclaimer: Not a paid promotion—though I am open to the idea if Screenpresso so wishes.
 ]
]